[Excel]献立作成ソフトを作ろう 第12回 レシピ作成シートの作成(9)
献立作成ソフトを作ろう第12回目は、レシピの手順から行頭文字や連番を自動的に除去する仕組みを作成します。そんな機能要らないよという人も、いつか役に立つ日が来ると信じてお付き合い下さい。
行頭文字や連番の発生源
現在作成中のレシピの手順には、文章の最初に「(1) (2) (3)・・・」という連番が付いていますね。本献立作成ソフトは、行頭文字や連番を自動で付加する仕組みを付けていますので、手順を最初から自分で手入力する場合は、このような連番が付くことはありません。しかし、過去に自作したレシピや、料理紹介サイトをコピーする場合は、行頭文字や連番が付いてきてしまうことがあります。これを本献立作成ソフトに貼り付けた際、行頭文字や連番が自動的に除去できたら便利ですよね?という訳で、これを実現する仕組みを作っていきます。

行頭文字や連番の種類を考える
仕組みづくりの前に、行頭文字や連番には、どんな種類があるか考えてみます。
まずは行頭文字ですが、下表の通りです。これ以外にも行頭文字に使えるものがありますが、この中に無いからといって自動除去出来ないわけではないので安心して下さい。
| 名称 | パターン1 | パターン2 |
| 中点 | ・ | (なし) |
| 丸 | ○ | ● |
| 二重丸 | ◎ | (なし) |
| 四角 | □ | ■ |
| ダイヤ | ◇ | ◆ |
| 三角 | △ | ▲ |
| 逆三角 | ▽ | ▼ |
| 星 | ☆ | ★ |
| ナンバー | # | (なし) |
次に連番です。連番の場合は行頭文字と異なり、数字と、数字と文章を区切る文字(区切文字)の組み合わせが発生するため、その数は「数字の種類×区切文字の種類」となります。区切文字は全角と半角の2種類が用意されているものもありますが、冗長なので全角は省略しました。
|
区切文字名称 |
アラビア数字 | ラテン文字 小文字 |
ラテン文字 大文字 |
ギリシャ文字 小文字 |
ギリシャ文字 大文字 |
ローマ数字 小文字 |
ローマ数字 大文字 |
| 小カッコ | (1) (2) (3) |
(a) (b) (c) |
(A) (B) (C) |
(α) (β) (γ) |
(Α) (Β) (Γ) |
(i) (ii) (iii) |
(I) (II) (III) |
| 小カッコ | {1} {2} {3} |
{a} {b} {c} |
{A} {B} {C} |
{α} {β} {γ} |
{Α} {Β} {Γ} |
{i} {ii} {iii} |
{I} {II} {III} |
| 大カッコ | [1] [2] [3] |
[a] [b] [c] |
[A] [B] [C] |
[α] [β] [γ] |
[Α] [Β] [Γ] |
[i] [ii] [iii] |
[I] [II] [III] |
| すみつきカッコ | 【1】 【2】 【3】 |
【a】 【b】 【c】 |
【A】 【B】 【C】 |
【α】 【β】 【γ】 |
【Α】 【Β】 【Γ】 |
【i】 【ii】 【iii】 |
【I】 【II】 【III】 |
| きっこうカッコ | 〔1〕 〔2〕 〔3〕 |
〔a〕 〔b〕 〔c〕 |
〔A〕 〔B〕 〔C〕 |
〔α〕 〔β〕 〔γ〕 |
〔Α〕 〔Β〕 〔Γ〕 |
〔i〕 〔ii〕 〔iii〕 |
〔I〕 〔II〕 〔III〕 |
| かぎカッコ | 「1」 「2」 「3」 |
「a」 「b」 「c」 |
「A」 「B」 「C」 |
「α」 「β」 「γ」 |
「Α」 「Β」 「Γ」 |
「i」 「ii」 「iii」 |
「I」 「II」 「III」 |
| 二重かぎカッコ | 『1』 『2』 『3』 |
『a』 『b』 『c』 |
『A』 『B』 『C』 |
『α』 『β』 『γ』 |
『Α』 『Β』 『Γ』 |
『i』 『ii』 『iii』 |
『I』 『II』 『III』 |
| 山カッコ | 〈1〉 〈2〉 〈3〉 |
〈a〉 〈b〉 〈c〉 |
〈A〉 〈B〉 〈C〉 |
〈α〉 〈β〉 〈γ〉 |
〈Α〉 〈Β〉 〈Γ〉 |
〈i〉 〈ii〉 〈iii〉 |
〈I〉 〈II〉 〈III〉 |
| 二重山カッコ | 《1》 《2》 《3》 |
《a》 《b》 《c》 |
《A》 《B》 《C》 |
《α》 《β》 《γ》 |
《Α》 《Β》 《Γ》 |
《i》 《ii》 《iii》 |
《I》 《II》 《III》 |
| 不等号1 | <1> <2> <3> |
<a> <b> <c> |
<A> <B> <C> |
<α> <β> <γ> |
<Α> <Β> <Γ> |
<i> <ii> <iii> |
<I> <II> <III> |
| 不等号2 | ≪1≫ ≪2≫ ≪3≫ |
≪a≫ ≪b≫ ≪c≫ |
≪A≫ ≪B≫ ≪C≫ |
≪α≫ ≪β≫ ≪γ≫ |
≪Α≫ ≪Β≫ ≪Γ≫ |
≪i≫ ≪ii≫ ≪iii≫ |
≪I≫ ≪II≫ ≪III≫ |
| ドット | 1. 2. 3. |
a. b. c. |
A. B. C. |
α. β. γ. |
Α. Β. Γ. |
i. ii. iii. |
I. II. III. |
| コロン | 1: 2: 3: |
a: b: c: |
A: B: C: |
α: β: γ: |
Α: Β: Γ: |
i: ii: iii: |
I: II: III: |
行頭文字や連番の自動除去
作業表の作成
さて、これらの行頭文字又は連番の、どのパターンが来ても除去する仕組みを作っていきます。これを1つの数式で表現すると複雑化する上、保守性も悪くなるため、作業表を作成します。下図の通りに作業表を作ってください。

文字入力が面倒な人のためにコピー&貼り付け用の表を用意しました。下表を全て選択してコピーし、レシピ作成シートのR57セルに「貼り付け先の書式に合わせる」で貼り付けて下さい。
| 行頭文字 自動除去作業表 | |||
| 行頭文字 | |||
| 区切文字 | |||
| 文字位置 | 手順1行目 | 一致 | 一致文字 |
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
出来ましたか?
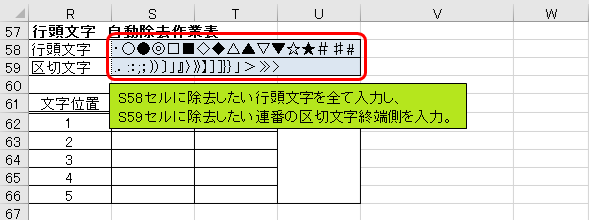
では、S58セルに除去したい行頭文字を全て入力します。S59セルには、除去したい連番の区切文字終端側を全て入力します。下表に入力文字のテンプレートを用意しておきますので、こちらをコピーしても問題ありません。しかし、ここに入力する文字は、必要に応じて選別しないと、誤作動を起こすことがありますので注意して下さい。
| 行頭文字 | ・○●◎□■◇◆△▲▽▼☆★#♯# | ||
| 区切文字 | ..::;;))〕」』〉》】]]}}」>≫> | ||
次に、入力した除去対象文字が、手順の先頭付近に含まれているかを検出する仕組みを作成していきます。
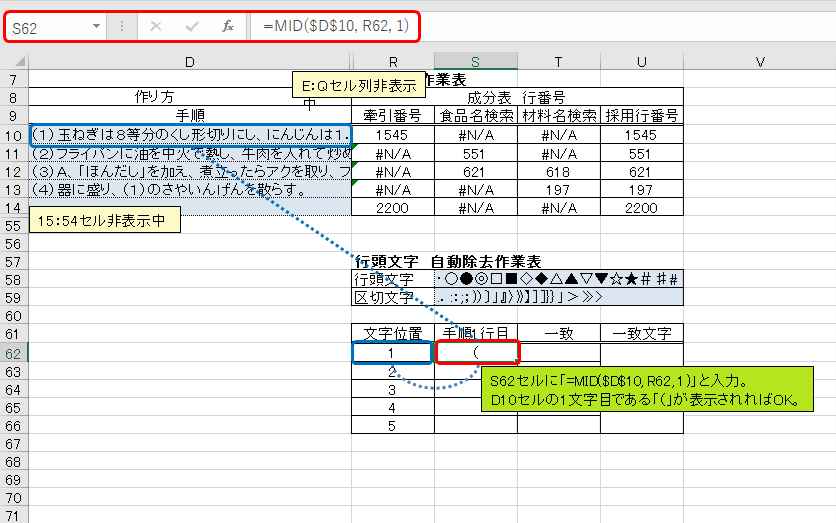
レシピの手順1行目(D10セル)の文字列から、文字を1つずつ取り出していきます。S62セルに「=MID($D$10, R62, 1)」と入力して下さい。D10セルの1文字目である「(」が表示されれば成功です。
MID関数という新しい関数が出てきましたね。MID関数は、引数で指定した文字列の一部を抜き出す関数です。MID関数の構文を下記に示します。
説明
文字列の任意の位置から指定された文字数の文字を返します。
書式
MID(文字列, 開始位置, 文字数)
| 引数 | 説明 | 引数の指定 | 既定値 |
|---|---|---|---|
| 文字列 | 取り出す文字を含む文字列を指定します。 | 必須 | (無し) |
| 開始位置 | 文字列から取り出す先頭文字の位置を数値で指定します。 文字列の先頭文字の位置が 1 になります。 | 必須 | (無し) |
| 文字数 | 取り出す文字数を指定します。 | 必須 | (無し) |
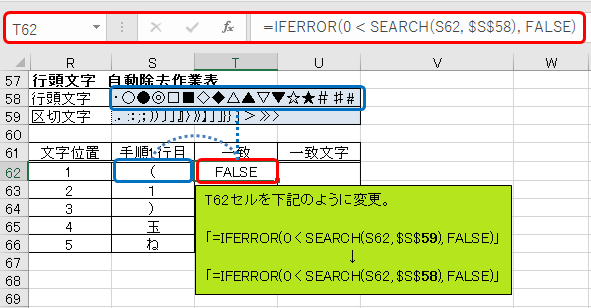
手順から取り出した文字が、除去したい文字であるかを判別していきます。T62セルに「=IFERROR(0 < SEARCH(S62, $S$59), FALSE)」と入力して下さい。S62セルの文字「(」がS59セル内の文字列に含まれていない場合、「FALSE」が表示されます。
この数式は後で少し変更するため、数式の説明は後述します。 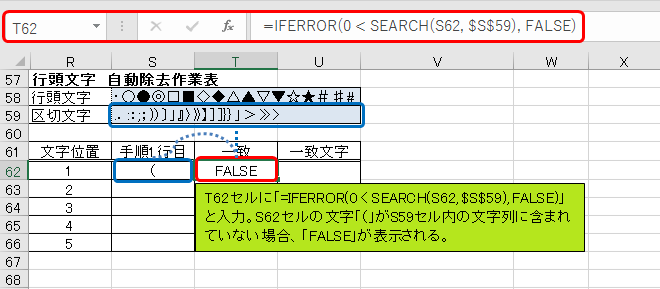
今度は、SEARCH関数という新しい関数が出てきました。SEARCH関数の構文を下記に示します。
説明
指定した文字列の中から、別に指定した文字列を検索し、その位置を返します。
書式
SEARCH(検索文字列,対象,[開始位置])
| 引数 | 説明 | 引数の指定 | 既定値 |
|---|---|---|---|
| 検索文字列 | 検索する文字列を指定します。ワイルドカードが使用可能です。 | 必須 | (無し) |
| 対象 | 検索文字列引数に指定した値を含む文字列を指定します。 | 必須 | (無し) |
| 開始位置 | 検索を開始する位置を指定します。 | 省略可能 |
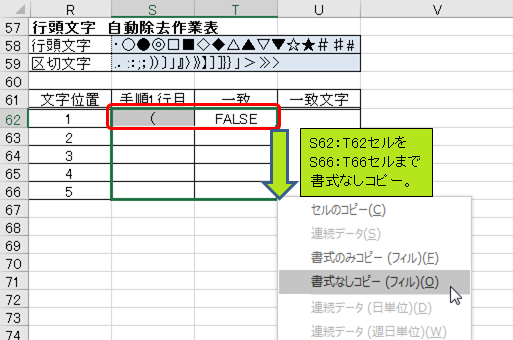
レシピ手順の5文字目までに、除去したい文字を含んでいるか判別するため、S62:T62セルをS66:T66セルまで書式なしコピーします。
ここで少し考えて頂きたいのですが、連番の区切文字終端側”)"や"."などは、必ず文章の2文字目以降に出現しますね(前述の連番表を参照のこと)。これに対して行頭文字"・"や"◆"は、必ず文章の1文字目に出現しますね。そのため、1文字目の判定は、S58セルに入力されている行頭文字で行います。
T62セルを下記のように変更します。
「=IFERROR(0 < SEARCH(S62, $S$59), FALSE)」
↓
「=IFERROR(0 < SEARCH(S62, $S$58), FALSE)」
では、先程入力した数式「=IFERROR(0 < SEARCH(S62, $S$58), FALSE)」について説明します。
SEARCH関数は、第1引数{検索文字列}で指定した文字列を、第2引数{対象}で指定した文字列の中から検索します。{検索文字列}を検出した場合は、検出位置を整数で返します。例えば、「=SEARCH(“a", “abc")」という数式は1を、「=SEARCH(“c", “abc")」という数式は3を返します。言い換えると、{対象}の中に{検索文字列}が含まれている場合、SEARCH関数は1以上の整数を返します。つまり、「= 0 < SEARCH({検索文字列},{対象})」という数式は、{対象}の中に{検索文字列}が含まれている場合、TRUEを返す数式となります。
しかしSEARCH関数は、{対象}の中に{検索文字列}が含まれない場合、エラー値#VALUE!を返します。すると、先の数式は「= 0 < #VALUE!」となり、結果は「#VALUE!」となります。これの見方を変えれば、SEARCH関数からエラー値が返ってきた場合は、{対象}の中に{検索文字列}を含まない、ということなので、IFERROR関数によってエラー値をFALSEに変換しています。
ここまでの一連の計算過程を示します。1文字目"("は行頭文字ではないため、結果はFALSEになります。
- =IFERROR(0 < SEARCH(S62, $S$58), FALSE)
- =IFERROR(0 < SEARCH(“(", “・○●◎□■◇◆△▲▽▼☆★#♯#"), FALSE)
=IFERROR(0 < SEARCH(“(", “・○●◎□■◇◆△▲▽▼☆★#♯#"), FALSE) - =IFERROR(0 < #VALUE!, FALSE)
=IFERROR(0 < #VALUE!, FALSE) - =IFERROR(#VALUE!, FALSE)
=IFERROR(#VALUE!, FALSE) - FALSE
今度は3文字目の計算過程を示します。3文字目")"は区切文字であるため、結果はTRUEになります。
- =IFERROR(0 < SEARCH(S64, $S$59), FALSE)
- =IFERROR(0 < SEARCH(“)", “..::;;))〕」』〉》】]]}}」>≫>"), FALSE)
=IFERROR(0 < SEARCH(“)", “..::;;))〕」』〉》】]]}}」>≫>"), FALSE) - =IFERROR(0 < 8, FALSE)
=IFERROR(0 < 8, FALSE) - =IFERROR(TRUE, FALSE)
=IFERROR(TRUE, FALSE) - TRUE
行頭文字又は区切文字を検出する仕組みが理解できたら、次に検出した除去対象文字を取得します。
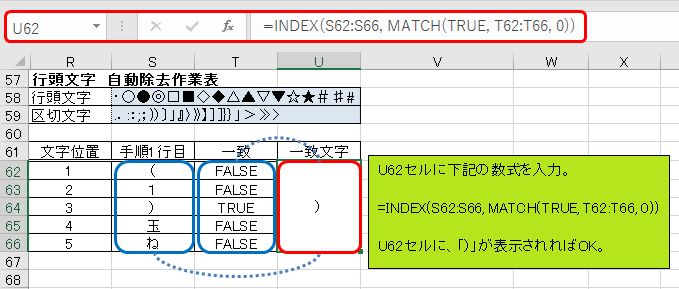
U62セルに「=INDEX(S62:S66, MATCH(TRUE, T62:T66, 0))」と入力して下さい。U62セルに、「)」が表示されれば成功です。INDEX-MATCH関数による検索はこれまでに何度も実施してきましたね。これはその応用です。
行頭文字と連番の自動除去
いよいよ、行頭文字と連番の自動除去機能を実装します。
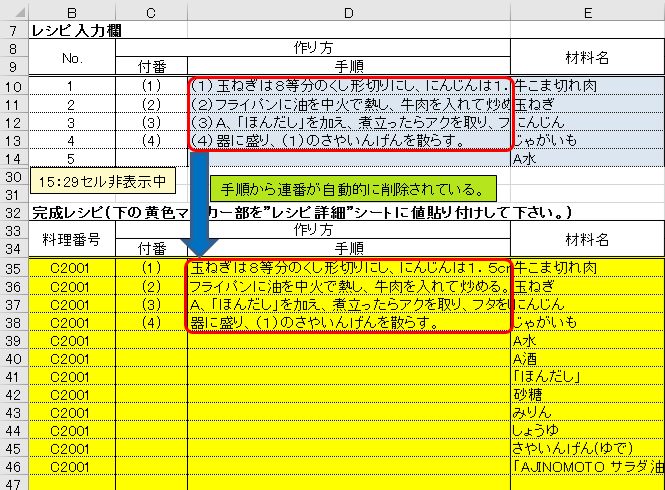
前回、U35セルには手順の単純な参照「=D10&""」が入力されているため、これを削除して、下記の数式を入力して下さい。
=IF(D10 = “", “", IFERROR(MID(D10, SEARCH($U$62, LEFT(D10, 5))+1, 9999), D10))
U35セルから連番”(1)”が削除されれば成功です。

今度はLEFT関数という新しい関数が出てきましたね。LEFT関数は、MID関数の第3引数{開始位置}に指定する値を1に固定した関数です。つまり、文字列の先頭から指定した文字数分の文字列を取得します。MID関数を理解していればLEFT関数も簡単に理解できるでしょう。
LEFT関数の構文を下記に示します。
説明
文字列の先頭 (左端) から指定された文字数の文字を返します。
書式
LEFT(文字列, [文字数])
| 引数 | 説明 | 引数の指定 | 既定値 |
|---|---|---|---|
| 文字列 | 取り出す文字を含む文字列を指定します。 | 必須 | (無し) |
| [文字数] | 取り出す文字数を指定します。 文字数には、0 以上の数値を指定する必要があります。 文字数が文字列の文字数を超える場合、文字列全体が返されます。 |
省略可能 | 1 |
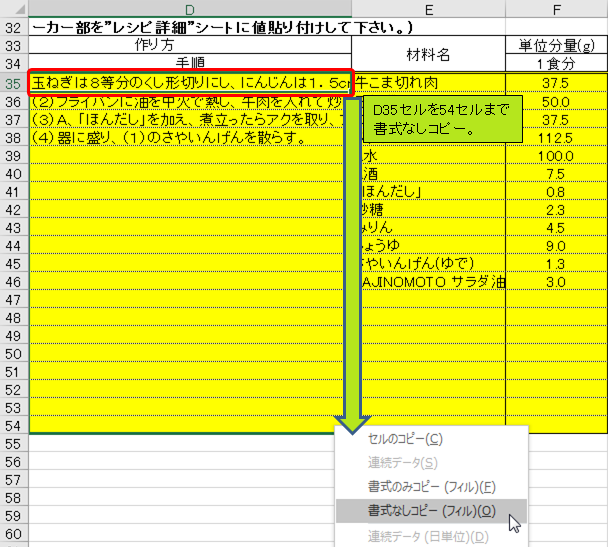
この数式をD35セルをD54セルまで書式なしコピーして完成です。
これで無事、全ての手順から連番が除去されました。
それでは、行頭文字と連番を除去する数式「=IF(D10 = “", “", IFERROR(MID(D10, SEARCH($U$62, LEFT(D10, 5))+1, 9999), D10))」について説明します。
この数式で最初に評価されるのはIF文ですが、これについては説明は不要でしょう。手順が空欄なら処理を中断して空文字を返しているだけです。
次に評価されるのはLEFT関数で、手順の最初の5文字を取得しています。これは、この数式の副作用を最小限にするためのもので、数式全体の説明したあとに説明します。
LEFT関数で取得した文字列"(1)玉ね"をSEARCHの第2引数{対象}に指定し、この中に除去対象文字列")"が含まれているかを確認します。この例では3文字目に除去対象文字列があるため、SEARCH関数は3を返します。これに1を加えて4にした数値を、MID関数の第2引数{開始位置}に指定します。第3引数{文字数}には9999を指定していますが、これは手順の文字数よりも必ず多くなる数値であれば、どんな数値でも構いません(Excelの仕様上限を超えなければ)。これにより、手順の中から、除去対象文字")"の次の文字"玉"から、最後の文字"。"まで切り出します。
最後にこの値をIFERROR関数に渡していますが、これはSEARCH関数が失敗した際の保険で、失敗した場合は、入力された手順をそのまま返します。
この数式の計算過程も確認してみましょう。
- =IF(D10 = “", “", IFERROR(MID(D10, SEARCH($U$62, LEFT(D10, 5)) + 1, 9999), D10))
- =IF(“(1)玉ねぎは…(中略)" = “", “", IFERROR(MID(D10, SEARCH($U$62, LEFT(D10, 5)) + 1, 9999), D10))
=IF(“(1)玉ねぎは…(中略)" = “", “", IFERROR(MID(D10, SEARCH($U$62, LEFT(D10, 5)) + 1, 9999), D10)) - =IF(FALSE, “", IFERROR(MID(D10, SEARCH($U$62, LEFT(D10, 5)) + 1, 9999), D10))
=IF(FALSE, “", IFERROR(MID(D10, SEARCH($U$62, LEFT(D10, 5)) + 1, 9999), D10)) - =IFERROR(MID(D10, SEARCH($U$62, LEFT(D10, 5)) + 1, 9999), D10)
=IFERROR(MID(D10, SEARCH($U$62, LEFT(D10, 5)) + 1, 9999), D10) - =IFERROR(MID(D10, SEARCH($U$62, LEFT(“(1)玉ねぎは…(中略)", 5)) + 1, 9999), D10)
=IFERROR(MID(D10, SEARCH($U$62, LEFT(“(1)玉ねぎは…(中略)", 5)) + 1, 9999), D10) - =IFERROR(MID(D10, SEARCH($U$62, “(1)玉ね") + 1, 9999), D10)
=IFERROR(MID(D10, SEARCH($U$62, “(1)玉ね") + 1, 9999), D10) - =IFERROR(MID(D10, SEARCH(“)", “(1)玉ね") + 1, 9999), D10)
=IFERROR(MID(D10, SEARCH(“)", “(1)玉ね") + 1, 9999), D10) - =IFERROR(MID(D10, 3 + 1, 9999), D10)
=IFERROR(MID(D10, 3 + 1, 9999), D10) - =IFERROR(MID(D10, 4, 9999), D10)
=IFERROR(MID(D10, 4, 9999), D10) - =IFERROR(MID(“(1)玉ねぎは…(中略)", 4, 9999), D10)
=IFERROR(MID(“(1)玉ねぎは…(中略)", 4, 9999), D10) - =IFERROR(“玉ねぎは…(中略)", D10)
=IFERROR(“玉ねぎは…(中略)", D10) - “玉ねぎは…(中略)"
さて、この数式におけるLEFT関数の役割を解説します。この数式では、手順の1行目から除去対象文字を選定し、この文字を2行目以降にも使用しています。ここで、2行目以降の手順の中に、除去対象の行頭文字が無かった場合を考えてみましょう。例えば、4行目の手順が"(4)器に盛り、(1)のさやいんげんを散らす。"ではなく、誤入力などにより"(4>器に盛り、(1)のさやいんげんを散らす。"となっていたり、"器に盛り、(1)のさやいんげんを散らす。"となっていた場合です。この場合、LEFT関数を通していないと、SEARCH関数は"(1)"の")"を検出し、この数式は"のさやいんげんを散らす。"という値を返してしまいます。これが、LEFT関数を通すと、SEARCH関数はエラー値#VALUEを返すため、"(4>器に盛り、(1)のさやいんげんを散らす。"を返します。少し不恰好になりますが、情報が失われる事態は回避できます。
この数式のアルゴリズムを理解している人であれば、LEFT関数を通さない場合でも、少し考えれば解決する話なので大きな問題にはなりません。しかし多くの場合、ソフトウェアの開発者と使用者は別の人です。そのため、想定されるエラーの対策は、可能な限り取っておくべきです。この数式のLEFT関数はその一例でした。
次回は、作成したレシピを保存しておくシートを作成します。
今日はここまで。