[Excel]献立作成ソフトを作ろう 第8回 レシピ作成シートの作成(5)
献立作成ソフトを作ろう第8回目のテーマは、検索機能の実装です。栄養計算に使用する食品の情報を、日本食品標準成分表から取得します。
本連載の第2回で、文部科学省のホームページから「日本食品標準成分表2015年版(七訂)」(以下、成分表と記載)をダウンロードしてワークシートを整形し、ワークシート名を「成分表」としました。今回は、このシートから目的の食品を検索し、名称やエネルギー、栄養成分などの食品情報を取得するための下準備をします。
検索というと、GoogleやYahoo!などのホームページ検索を連想する方も多いかと思います。本記事を読んでいる方も、この検索によって本サイトに辿り着いたことでしょう。もしこのサイトを繰り返し参照したいと思った方がいれば、このサイトのURLをブックマーク(又はお気に入り)に登録するでしょう。成分表から食品情報を検索する場合も基本的な流れは同じで、食品情報を取得したい食品に関連するキーワード(名称、部位、加工方法など)をセルに入力し、目的の食品を特定します。また、よく使う食品は、そのIDを覚えておいて、直接IDを指定することもできます。このIDは食品に対してユニークであれば何でも良いのですが、本講義では成分表に最初から入力されている牽引番号を使用します。ユニークの意味が分からない方は、第3回の”一意に識別するIDとは”を復習してください。
牽引番号による食品情報の取得
ワークシート間のセル参照
はじめに、牽引番号から食品情報を取得する数式を実装します。牽引番号はG10:G29セルに入力します。なお、今回は「成分表」と「レシピ作成シート」の2つのワークシートを使用するため、本記事内でシート名を指定しないセル参照は、「レシピ作成シート」のセル参照であると判断してください。つまり、前述のG10:G29セルは「レシピ作成シート」のセル参照を意図しています。ところで、これまでセル参照は列番号と行番号のみで指定してきました。改めて書くと混乱するかもしれませんが、普通に「=A1」といったセル参照のことを言っています。実はこのセル参照は、省略された記載方法です。「レシピ作成シート」のA1セルを少し長く書くと「=レシピ作成シート!A1」となります。ワークシート名とセルアドレスの間に「!」(エクスクラメーション)が入っていますね。「成分表」のA1セルなら「=成分表!A1」です。このようなセル参照を使用することで、「レシピ作成シート」内で「成分表」のセルの値を使用することができます。しかし、1つのワークシート内で事が済む場合は、わざわざワークシート名を指定する必要はありません。これは、学校や職場などの会話で、自分と同じクラス又は部署の「佐藤さん」の話題をする際は、単に「佐藤さん」と言いますが、違うクラスや部署の「佐藤さん」の場合は、「3組の佐藤さん」や「総務課の佐藤さん」と言うのと一緒です。セル参照にワークシート名が指定されていない場合、Excelは暗黙的に、入力されたセルと同じワークシートのセル参照であると判断しています。
MATCH-INDEX検索
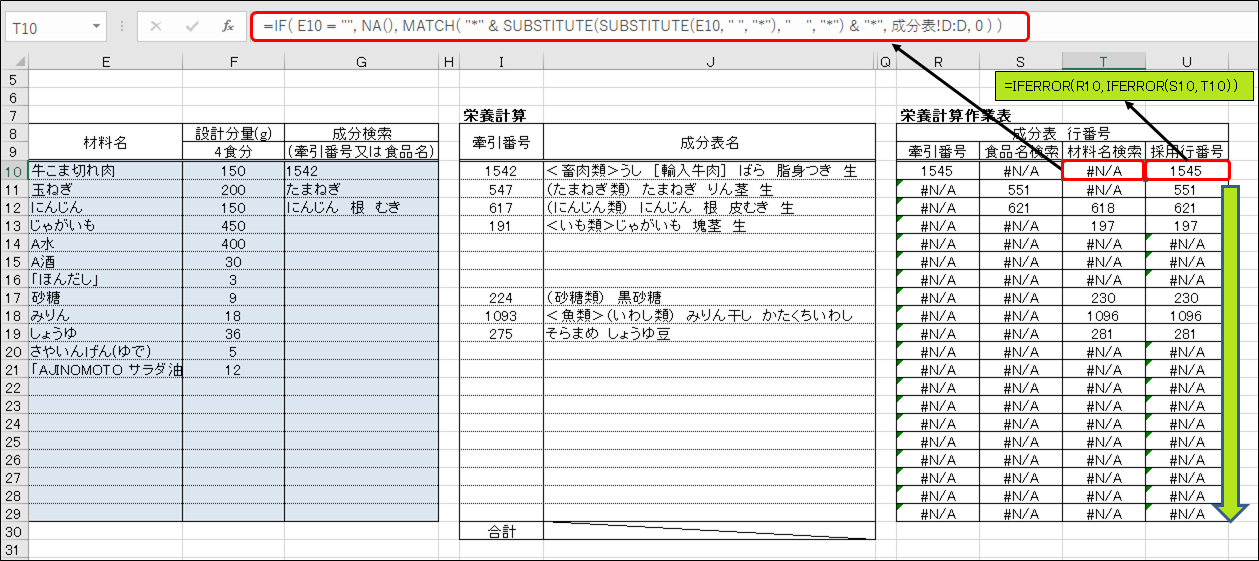
牽引番号により食品情報を取得するため、今回は牛こま切れ肉の牽引番号を手動で調べます。
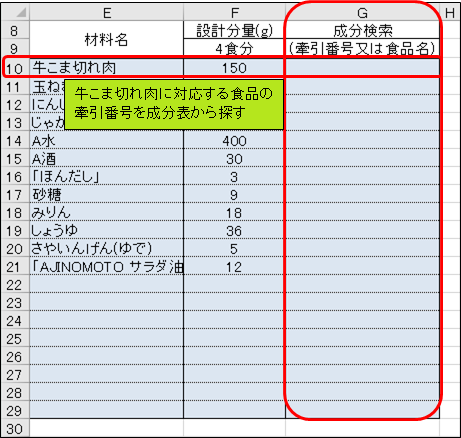
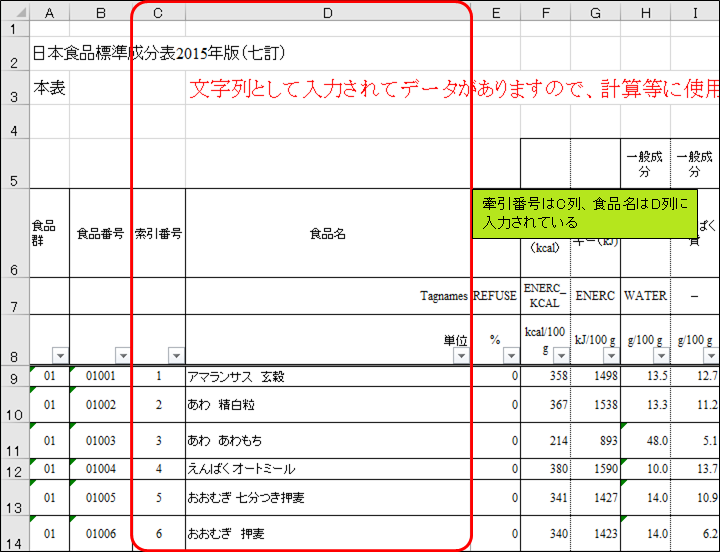
ところで、”こま切れ肉”は特定の部位の名称ではなく、肉の切れ端の総称です。従って、成分表には”こま切れ肉”という食品名は存在しません。今回は便宜上、輸入牛肉のばら肉を栄養計算に使用します。「成分表」では、牽引番号はC列に、食品名はD列に入力されています。
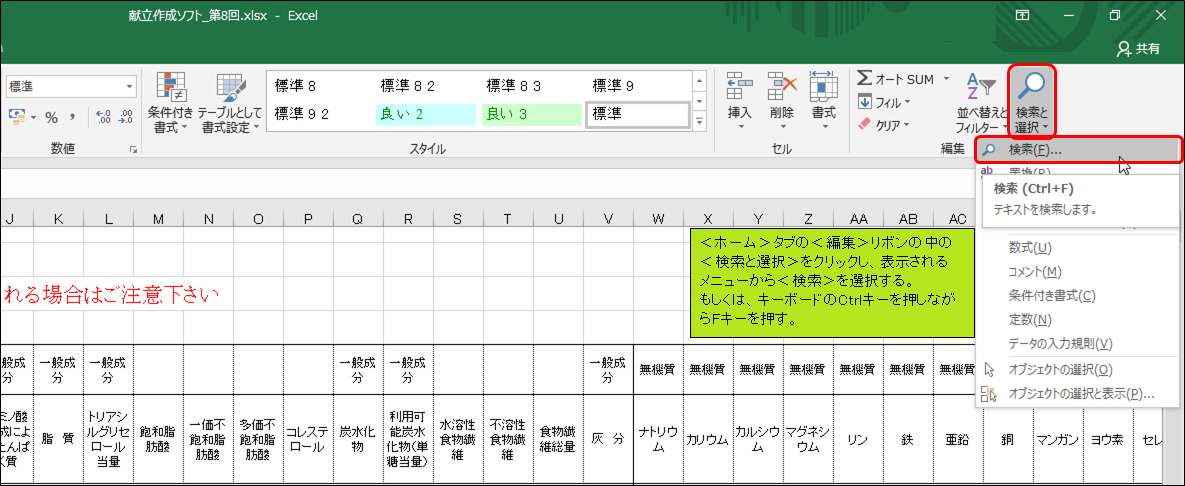
まずは手動で、輸入牛肉のばら肉を探してみましょう。手動といっても、Excel標準の検索機能を使用します。<ホーム>タブの<編集>リボンの中から、<検索と選択>をクリックし、表示されるメニューから<検索>を選択します。もしくは、キーボードのCtrlキーを押しながらFキーを押しても良いです(慣れるとこっちの方が早いです)。
<検索と置換>ダイアログが表示されるため、<検索する文字列>テキストボックスに「ばら」と入力し、<次を検索>ボタンを押して下さい。アクティブセルから左下に検索して最初に「ばら」と入力されているセルが選択状態となります。
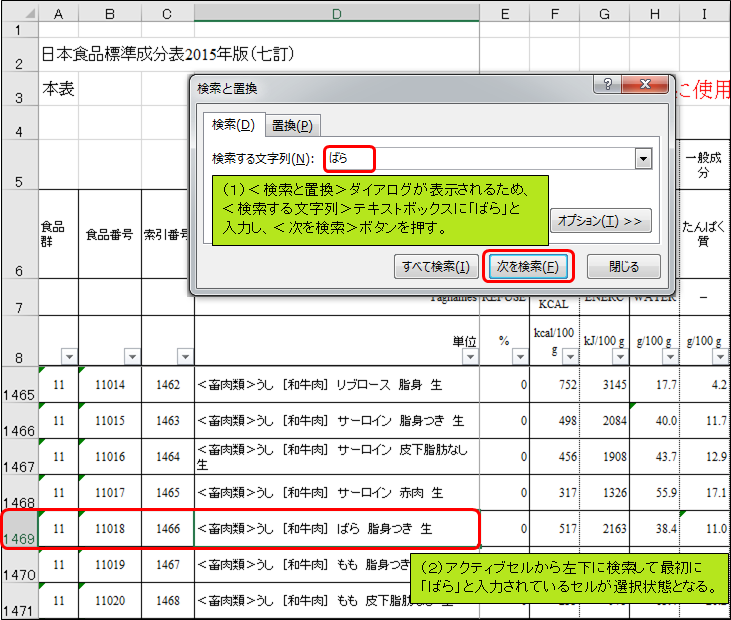
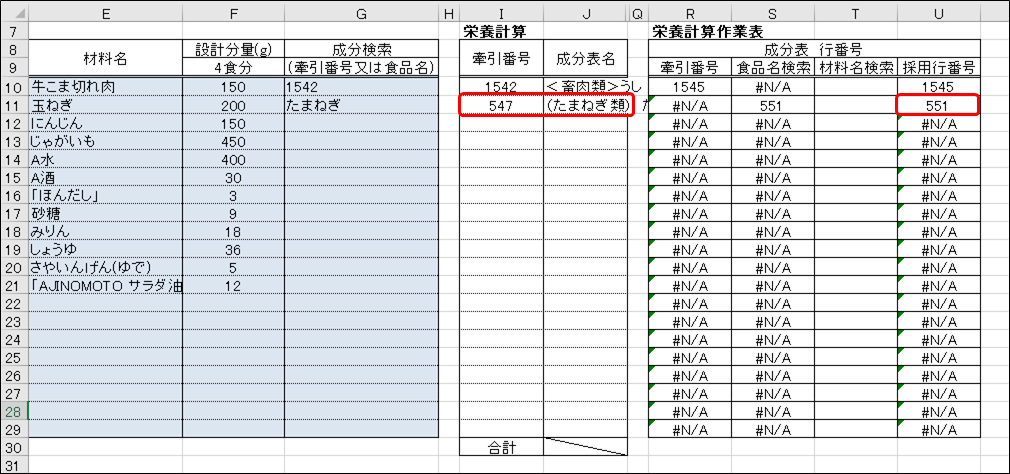
<次を検索>ボタンを合計5回押すと、1545行目にある「<畜肉類>うし [輸入牛肉] ばら 脂身つき 生」が選択されます。探していたのは輸入牛肉のばら肉でしたね。これを、”牛こま切れ肉”に対応する食品としましょう。牽引番号は「1542」です。行番号と値が似ていますが、混同しないようにしましょう。
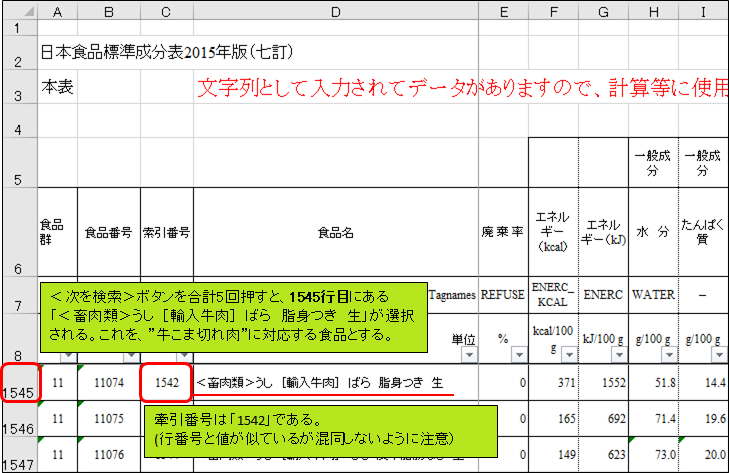
「レシピ作成シート」に戻り、G10セルに先程の牽引番号「1542」を入力します。

この牽引番号を使って、食品情報を取得しましょう。これには、MATCH関数とINDEX関数を使用します。
一応、MATCH関数の構文を下記に示しますが、枠の中の内容を全て読む必要はありませんし、現時点で理解できなくても構いません。まずはMATCH関数を使ってみて、応用してみたくなったり、挙動を確認したくなったら、改めて読んでみて下さい。
構文
MATCH(検査値, 検査範囲, [照合の型])
|
引数名 |
説明 |
| 検査値 | 必ず指定します。検査範囲の中で照合する値を指定します。たとえば、電話番号帳を使ってある人の電話番号を調べるとき、検査値としてその人の氏名を指定しますが、実際に検索するのは電話番号です。
検査値には、値 (数値、文字列、または論理値)、またはこれらの値に対するセル参照を指定できます。 |
| 検査範囲 | 必ず指定します。検索するセルの範囲を指定します。 |
| [照合の型] | 省略可能です。-1、0、1 の数値のいずれかを指定します。照合の型には、検査範囲の中で検査値を探す方法を指定します。この引数の既定値は 1 です。 |
次の表は、照合の型に基づいて関数が値を検索する方法を示しています。
| 照合の型 | 動作 |
| 1 または省略 | MATCH 関数は、検査値以下の最大の値を検索します。検査範囲の引数の値は、昇順の並べ替えでは、1 ~ 9、A ~ Z、あ~ん、FALSE ~ TRUE の順に配置されます。 |
| 0 | MATCH 関数は、検査値と等しい最初の値を検索します。検査範囲の引数の値は、任意の順序で指定できます。 |
| -1 | MATCH 関数は、検査値以上の最小の値を検索します。検査範囲の引数の値は、降順の並べ替えでは、9 ~ 1、Z ~ A、ん~あ、TRUE ~ FALSE の順に配置されます。 |
- MATCH関数は、指定したセルに含まれている値ではなく、検査範囲内にある検査値に一致する値の位置を返します。たとえば、MATCH(“b",{“a","b","c"},0) は 2 を返します。これは、配列 {“a","b","c"} の中での “b" の相対位置を表します。
- MATCH関数では、英字の大文字と小文字は区別されません。
- MATCH関数で検査値が見つからない場合は、#N/A エラー値が返されます。
- 検索の型が 0 で、検索値が文字列の場合は、 検査値の引数で、疑問符(?) やアスタリスク (*) をワイルドカード文字として使用できます。ワイルドカード文字の疑問符は任意の 1 文字を表し、アスタリスクは 1 文字以上の任意の文字列を表します。ワイルドカード文字ではなく、通常の文字として疑問符やアスタリスクを検索する場合は、その文字の前に半角のチルダ (~) を付けます。
では、MATCH関数を使ってみましょう。R10セルに「=MATCH( $G10 , 成分表!C:C , 0 )」と入力してEnterキーを押して下さい.セル参照$G10が列番号だけ絶対参照になっていますが、これは後ほど効果を発揮します。MATCH関数の第1引数には、いわゆる検索キーワードを指定します。今回は牽引番号を指定します。第2引数は、検索キーワードを検索する範囲で、今回は「成分表」のC列全体を指定します。第3引数は検索方法を指定する引数ですが、特別な事情が無い限り「0」を指定しておけば問題ありません。

R10セルに「1545」と表示されればMATCH関数は成功です。このセルをR29まで書式なしコピーして下さい。さて、この「1545」ですが、これは「成分表」の行番号を示しており、「成分表」の1545行目には「<畜肉類>うし [輸入牛肉] ばら 脂身つき 生」の情報が入力されています。つまりこの数式は、牽引番号「1542」を使用して、牽引番号に対応する食品情報が入力されている行番号を取得します。

MATCH関数について、もう少し詳しく解説します。MATCH関数は、第1引数で指定した値を、第2引数で指定した範囲の中から探します。今回の「=MATCH( $G10 , 成分表!C:C , 0)」の計算過程を見てみましょう。
と、その前に、複数のセル参照(成分表!C:C やA1:A10など)が数式の計算過程でどう解釈されるかを説明します。複数のセル参照は、計算過程で配列というものに変換されます。配列の定義は下記の通りです。定義はよく分からなくても大丈夫です。
配列とは、複数のデータを連続的に並べたデータ構造。各データをその配列の要素といい、自然数などの添字(インデックス)で識別される。(weblio辞書より引用)
配列とは、複数の値を1つにまとめたものです。例えばE10:E12セルを配列に変換すると、その値は「{ “牛こま切れ肉" , “玉ねぎ" , “にんじん" }」となります。F19:F21なら「{ 36 , 5 , 12 }」ですね。Excelの場合、複数の値を「 , 」で区切り、その先頭に「 { 」、末尾に「 } 」を付けると、Excelはこれを配列と判断します。配列の中の値を要素と言い、{}内の要素がいくつあっても、配列は1つと数えます。第7回では下記のように、SUM関数を例に引数の数の数え方を説明しました。
K30セルに「=SUM(K10:K29)」と入力してEnterキーを押します。この場合の引数の数は、セル参照K10:K29の1つです。セルの数は20個ですが、引数としては1個のセル参照として数えます。しかし、「=SUM(K10,K11,K12)」とした場合の引数は3つと数えます。(本連載第7回より引用)
このセル参照K10:K29を引数1つと数えるのは、計算過程で1つの配列(要素数は20個)に変換されるためです。なお、配列は数式中に直接記述することもできます。例えば、「=SUM( { 1 , 2 , 3}) 」の戻り値は「6」となります。このように、数式内で直接記述した配列を配列定数と言います。
前置きが長くなりましたが、改めて「=MATCH( $G10 , 成分表!C:C , 0)」の計算過程を見てみましょう。なお、「成分表!C:C」の要素数は2199個(厳密には1048576個)なので、書ききれない途中の要素は省略しています。中略1では、1532個の要素を、中略2では651個の要素を省略しています。
- =MATCH( $G10 , 成分表!C:C , 0 )
- =MATCH( “1542″ , { “" , “" , “" , “" , “" , “索引番号" , “" , “" , “1" , “2" , “3" , (中略1) , “1541" , “1542" , “1543" , (中略2) , “2197" , “2198" } , 0 )
(青マーカー部が配列)
ここで、MATCH関数は第1引数で指定した値(“1542")を第2引数の配列の中から検索します。配列の中から一致するものが見つからなかった場合、MATCH関数は「#N/A」を返します。一致するものが見つかった場合、MATCH関数は一致した要素のインデックスを返します。要素のインデックスとは、配列内における要素の位置番号のことです。位置番号は、配列の先頭を1として数えます。例えば、配列{ “A" , “B" , “C" }において、要素"C"のインデックスは「3」です。
今回のMATCH関数をIF関数風に書くと下記のようになります。ここで、「"1542″」は牽引番号、太字は配列内の要素、斜体は配列要素のインデックスです。
- =IF( “1542" = “" , 1 , (次のIF関数を実行) )
- =IF( “1542" = “" , 2 , (次のIF関数を実行) )
- (中略)
- = IF( “1542" = “牽引番号" , 6 , (次のIF関数を実行) )
- =IF( “1542" = “" , 7 , (次のIF関数を実行) )
- =IF( “1542" = “" , 8 , (次のIF関数を実行) )
- =IF( “1542" = “1″ , 9 , (次のIF関数を実行) )
- =IF( “1542" = “2″ , 10 , (次のIF関数を実行) )
- (中略)
- = IF( “1542" = “1541″ , 1544 , (次のIF関数を実行) )
- =IF( “1542" = “1542″ , 1545 , (次のIF関数を実行) ) ←今回はコレが一致
- (中略)
- =IF( “1542" = “2198″ , 2199 , #N/A )
MATCH関数の動きが理解できたでしょうか?今回の数式「=MATCH( $G10 , 成分表!C:C , 0)」では、戻り値をそのまま行番号として使用していますが、厳密に言うと、MATCH関数の戻り値は配列要素のインデックスです。MATCH関数の第2引数に指定するセル参照の範囲(今回は「成分表!C:C」)が、ワークシートの1行目を含んでいる場合、配列要素のインデックスとワークシートの行番号は同じ値となります。MATCH関数の第2引数がワークシートの1行目を含んでいない場合、例えば「成分表!C2:C9999」である場合、MATCH関数の戻り値(配列要素のインデックス)は、ワークシートの行番号より1少ない値を返します。この性質は別の機会に使用します。とりあえず覚えてほしいのは、MATCH関数は、ワークシートの行番号を返す関数ではなく、第2引数で指定した配列の要素のインデックスを返す関数であるということです。
話を本題に戻します。先程コピーしたR11:R29セルが全てエラー値「#N/A」となっていますが、特に問題はありません。MATCH関数は、キーワード(第1引数)に空の文字列「""」を指定すると「#N/A」を返します。つまり、牽引番号入力セルであるG11:G29セルが空欄であるため、R11:R29セルのMATCH関数が第1引数に「""」を受け取り、戻り値が「#N/A」となった結果です。牽引番号入力セルに有効な(成分表に存在する)牽引番号を入力すれば、対応する行番号が表示されます。
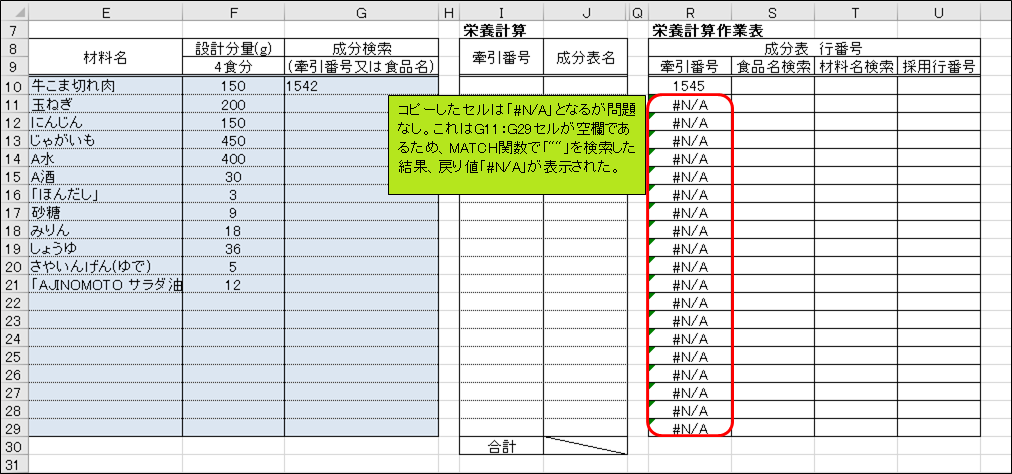
次に、U10セルにR10のセル参照を入力し、U29セルまで書式なしコピーして下さい。このU10:U29セルのタイトルは”採用行番号”と書いてありますね。現時点で、このセルはR10:R29セルと同一の値であるため、存在意義が分かりませんが、後ほど変更を加えます。具体的には、ユーザーが食品情報を検索する際、検索キーワードとして牽引番号の他に、成分表の食品名や「レシピ作成シート」の材料名(E10:E29セル)を使用できるようにするためのセルです。
さて、牽引番号を指定して、成分表から目的の食品情報が入力されている行番号を取得しました。この行番号を使用して、実際に食品情報を取得してみましょう。これには、INDEX関数を使用します。INDEX関数は、指定したセル参照範囲(領域とも言います)の中から、行番号と列番号で指定したセル参照を取得する関数です。言い換えると、通常はセルアドレス(A1など)で指定しているセル参照を、動的に指定するための関数です。例によって下記にINDEX関数の構文を示しますが、こちらも、枠の中の内容を全て読む必要はありませんし、現時点で理解できなくても構いません。
|
引数名 |
説明 |
| 対象範囲 | 必須。1 つまたは複数のセルの参照を指定します。
|
| 行番号 | 必須。範囲の中にあり、セル参照を返すセルの行位置を数値で返します。 |
| [列番号] | 任意。範囲の中にあり、セル参照を返すセルの列位置を数値で返します。 |
| [領域番号] | 任意。行番号と列番号が交差する位置を返す参照の範囲を 1 つ選択します。最初に選択または入力された領域の領域番号が 1 となり、以下、2 番目の領域は 2 というように続きます。領域番号を省略すると、INDEX で領域 1 が使用されます。 ここで表示される領域はすべて 1 つのシート上に置かれている必要があります。 他の領域と同じシート上に存在しない領域を指定した場合、#VALUE! エラーが発生します。 相互に異なるシート上に置かれている範囲を使用する必要がある場合は、INDEX 関数の配列形式を使用し、別の関数を使用して配列を形成する範囲を計算することをお勧めします。 たとえば、CHOOSE 関数を使用して、どの範囲が使用されるかを計算することができます。 |
たとえば、範囲として (A1:B4,D1:E4,G1:H4) のような複数選択領域が指定されている場合、領域番号の 1 は A1:B4、領域番号の 2 は D1:E4、領域番号の 3 は G1:H4 となります
さっそく使ってみましょう。I10セルに「INDEX(」まで入力し、「成分表」をクリックします。

「成分表」の列番号「C」をクリックすると、数式に「成分表!C:C」が自動入力され、「=INDEX(成分表!C:C」となります。この操作は,「成分表!C:C」を一語一句正確に入力できるなら手入力でも構いません。
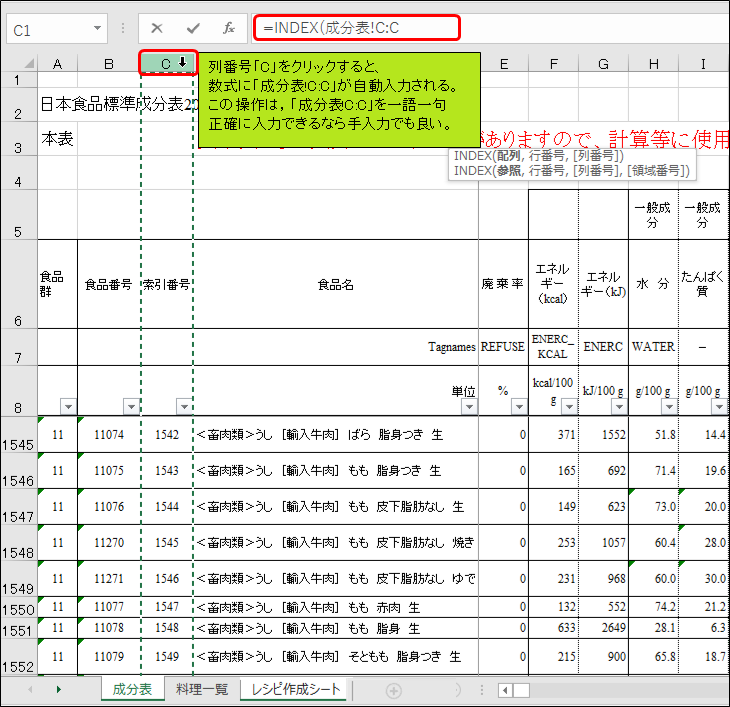
「成分表!C:C」を自動入力させた場合、数式バーをクリックして、数式の末尾にキーボードで「 , 」を入力して下さい。これは、セル参照の自動入力を確定させるためです。自動入力を確定させないまま、マウスやキーボードの矢印キーで別のセルを選択すると、そのセルの参照が自動入力されてしまいます。自動入力を確定させるために入力する文字は「 , 」に限らず何でも構いませんが、何も入力したくない場合はF2キーかEnterキーを押します。
「レシピ作成シート」に戻るためシート名をクリックすると、数式の末尾(正確にはキャレットの位置)にこのシートの参照である「レシピ作成シート!」が自動入力されます。見易さの観点から削除しても構いません。本記事では削除します。
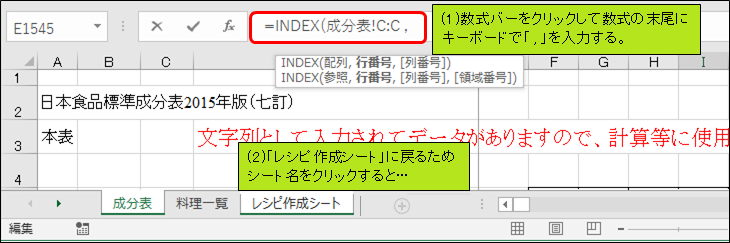

数式の末尾に「 $U10 , 1) 」を入力して数式「=INDEX(成分表!C:C, $U10, 1)」を完成させ、Enterキーを押します。「成分表」シートのC列1545行目の値(牽引番号)「1542」が表示されればOKです。牽引番号「1542」は、既にG10セルに手入力しているため、何の意味があるか分からない方もいるかもしれませんが、もう少し読み進めると意味が分かってくると思います。

INDEX関数は、第1引数で指定したセル参照の範囲(又は配列)の中から、第2引数と第3引数で指定した行数と列数に該当する値を返します。最も簡単なINDEX関数の一例は「=INDEX(E10 , 1 , 1)で、戻り値は「"牛こま切れ肉"」です。この数式の意味は「=E10」と同じです。次に、「=INDEX(E10:E29 , 1 , 1)」の場合を考えてみましょう。最初の例と比較して、第一引数のセル参照が範囲になりましたね。この場合でも、戻り値は「"牛こま切れ肉"」で、数式の意味は「=E10」と同じです。では次に、「=INDEX(E10:E29 , 2 , 1)」ではどうでしょうか?今回は第2引数(行数)に「2」を指定しています。この場合の戻り値は「"玉ねぎ"」で、数式の意味は「=E11」と同じです。この数式を言葉にすると、E10~E29セルの中から、E10を原点として2行目、1列目に該当するセル参照を取得します。では最後に、「=INDEX(E10:E29 , 3 , 1)」ではどうでしょうか?もうお分かりですね。戻り値は「"にんじん"」、数式の意味は「=E12」と同じです。
では、「=INDEX(成分表!C:C, $U10, 1)」の計算過程を見てみましょう。今回も「成分表!C:C」の途中の要素は省略しています。なお、Excelはセル参照を配列の要素として指定できませんが、計算過程を理解してもらうため、便宜上配列の要素としてセル参照を記載しています。また、分かり易さのために、セル参照の隣にセルの値を併記しました。
- =INDEX( 成分表!C:C , $U10 , 1 )
- =INDEX( { 成分表!C1(“") , 成分表!C2(“") , (中略) , 成分表!C6(“索引番号") , 成分表!C7(“") , (中略) , 成分表!C1544(1541) , 成分表!C1545(“1542") , 成分表!C1546(“1543" ), (中略) , 成分表!C2198(“2197") , 成分表!C2199(“2198")} , “1545″ , 1 )
(青マーカー部が配列)
ここでINDEX関数は、成分表!C1セルを原点として1545行目、1列目に該当するセル参照を返します。今回、第1引数のセル参照(成分表!C:C)は1列であるため、第3引数で指定する列数は1以外指定できません。列数に2以上の値を指定すると、第1引数のセル参照の範囲外を指定していることになるため、戻り値は「#REF!」となります。これは、行数に1048577(ワークシートの最大行数+1 )を指定しても同様です。
今回のINDEX関数をIF関数風に書くと下記のようになります。ここで、「1545」は行番号、太字は第1引数で指定したセル参照の行数(配列要素のインデックスと同じ)、斜体はセル参照です。
- =IF( 1545 = 1 , 成分表!C1(“") , (次のIF関数を実行) )
- =IF( 1545 = 2 , 成分表!C2(“") , (次のIF関数を実行) )
- (中略)
- = IF( 1545 = 6 , 成分表!C6(“牽引番号") , (次のIF関数を実行) )
- =IF( 1545 = 7 , 成分表!C7(“") , (次のIF関数を実行) )
- (中略)
- = IF( 1545 = 1544 , 成分表!C1544(“1541") , (次のIF関数を実行) )
- =IF( 1545 = 1545 , 成分表!C1545(“1542") , (次のIF関数を実行) ) ←今回はコレが一致
- (中略)
- =IF( 1542 = 2199 , 成分表!2199(“2198") , #REF! )
なお、実際のINDEX関数は、上記のIF関数風処理とは違って、インデックスを1回1回比較しません。つまり、インデックスに対応する配列要素(セル参照)を1回で引き当てます。
INDEX関数の動きが理解できたでしょうか?MATCH-INDEX検索を行う場合、MATCH関数の第2引数のセル参照の行数と、INDEX関数の第1引数のセル参照の行数は一致させる必要があります。この言葉の意味が理解できると、MATCH-INDEX検索の基本を理解できたと思ってください。
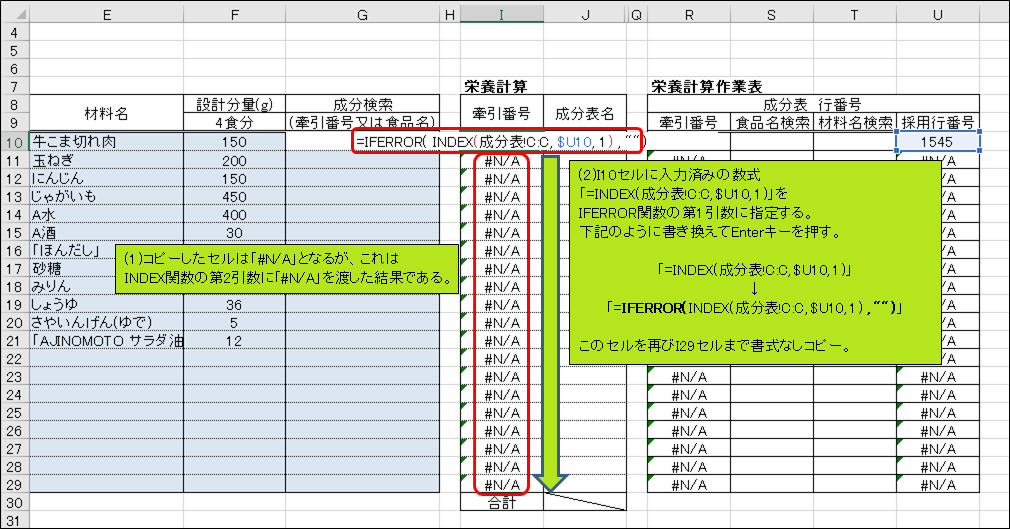
話を本題に戻します。I10セルをI29セルまで書式なしコピーして下さい。コピーしたセルは「#N/A」となりますが、これはINDEX関数の第2引数に「#N/A」を渡した結果です。

INDEX関数に限らす、多くの関数は、引数にエラー値を渡すと、戻り値は引数で渡したエラー値となります。これには例外もあり、エラー値を引数に取ることを前提としているISERROR関数やIFERROR関数などは、その関数毎の戻り値を返します。実際にIFERROR関数を試してみましょう。下記にIFERROR関数の構文を示します。
構文
IFERROR(値, エラーの場合の値)
|
引数名 |
説明 |
| 値 | 必ず指定します。 エラーかどうかをチェックする引数です。 |
| エラーの場合の値 | 必ず指定します。 数式がエラーと評価された場合に返す値。 評価されるエラーの種類には、#N/A、#VALUE!、#REF!、#DIV/0!、#NUM!、#NAME? または #NULL! があります。 |
IFERROR関数は、エラー値(#N/A、#VALUE!など)に限定したIF関数のようなもので、Excel2007から登場した比較的新しい関数です(10年以上経過しているので新しくもないのかもしれませんが)。
I10セルに入力済みの数式「=INDEX(成分表!C:C, $U10, 1)」は、エラー値#N/Aになる可能性があるため、これをIFERROR関数の第1引数に指定します。具体的には、I10セルの数式「=INDEX(成分表!C:C, $U10, 1)」を「=IFERROR( INDEX(成分表!C:C, $U10, 1) , “") 」に書き換えます。このセルを再びI29セルまで書式なしコピーして下さい。
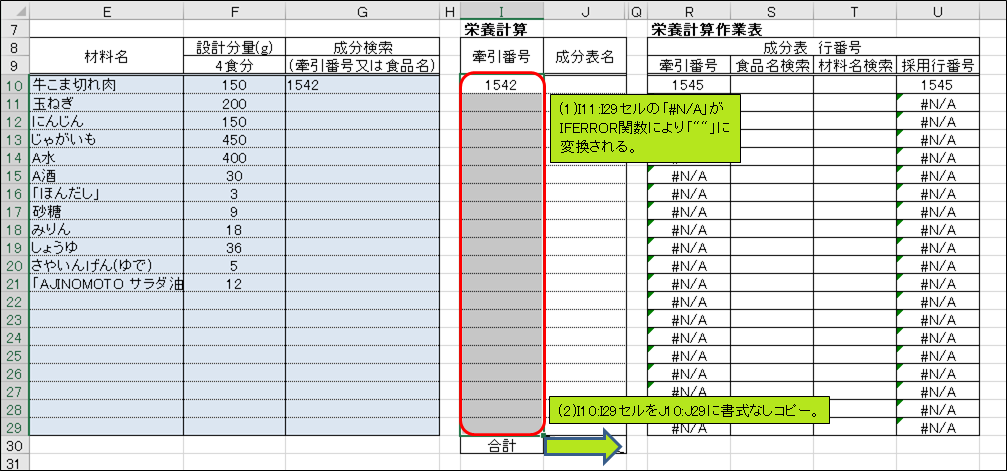
I11:I29セルの「#N/A」がIFERROR関数により「""」に変換され、エラー値の表示が無くなりました。とても見栄えが良くなりましたね。
スッキリした所で、I10:I29セルをJ10:J29セルに書式なしコピーして下さい。J10セルに、牽引番号「1542」に対応する食品名「<畜肉類>うし [輸入牛肉] ばら 脂身つき 生」が表示されました。これはある意味偶然ですが、詳しくは後述します。ついに、牽引番号から食品名を取得することが出来ました。牽引番号から食品名を取得できたということは、成分表の他の情報、つまりカロリーやたんぱく質量なども取得できそうな感じがしてきましたね。

ここで一度、数式を確認しておきましょう。I10:I29セルをJ10:J29にコピーした際、I列の数式の「成分表!C:C」が、J列では「成分表!D:D」に変化していますね。横方向にセルをコピーすると、相対参照のセル参照は列番号が変化します。横方向のコピーの場合も、$マークが付いた絶対参照$U10~$U29は変化していませんね。しかし、$U10は列番号のみの絶対参照であるため、I10セルをI11:I29セルにコピーした際、行番号は変化していたことも確認できます。つまり、I10:I29セルとJ10:J29セルの数式を比較して違うところは、INDEX関数の第1引数のみです。具体的には、I10:I29セルを1列右のJ10:J29セルにコピーしたことで、INDEX関数の第1引数が「成分表!C:C」から「成分表!D:D」に変化しました。J10:J29セルは成分表の食品名を表示する枠として事前に罫線を引いており、「成分表」のD列は偶然にも食品名が入力されてる列でした。結果として、セルのコピーだけで目的の値を取得する数式が出来ましたので、これはこのまま使用します。そして、INDEX関数の第1引数が「成分表!C:C」なら牽引番号を取得し、「成分表!D:D」なら食品名を取得するなら、この引数を書き換えることで、「成分表」の任意のセルの値を取得することが可能となります。例えば、「成分表!E:E」なら廃棄率、「成分表!F:F」ならカロリーを取得可能です。

食品名による食品情報の取得
牽引番号により食品情報を取得することができました。次に、食品名による検索を実装します。基本的な考え方は牽引番号の場合と同じです。
まず、R10:R29セルをS10:S29にコピーします。
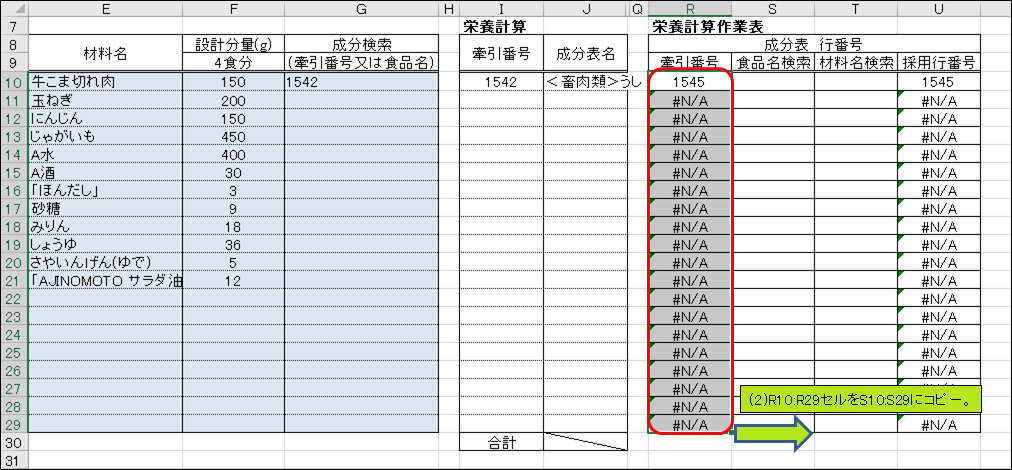
ここで、S11セルの数式が、成分検索セル(G11セル)をキーとして、食品成分表のD列(食品名)をMATCH関数で検索する数式になっていることを確認して下さい。R10セルの数式(特に$マーク)が本講義の通りに入力されていれば、ここまで辿り着く過程で自動的にこのような数式になっています。

さっそく食品名で検索してみましょう。材料名G11セルの入力値は「玉ねぎ」ですが、食品成分表で玉ねぎはひらがなであるため、G11セルに「たまねぎ」と入力しましょう。これでS11セルに「たまねぎ」の行番号が取得できれば期待通りですが、S11セルは「#N/A」のままです。何故でしょうか?

困ったので「成分表」から手動でたまねぎの行を検索します。すると、「成分表」の551行目に「(たまねぎ類) たまねぎ りん茎 生 」がありました。食品名に”たまねぎ”という文字列を含んでいるのに、なぜ上手くいかないのでしょうか?実は、MATCH関数で文字列を検索する場合、キーワードと完全一致するセルが見つからないと、「#N/A」を返します。つまり、今回のケースでは、G11セルに「(たまねぎ類) たまねぎ りん茎 生 」と入力しないと、たまねぎの行番号を取得できません。さすがに「成分表」の食品名を空白を含めて一語一句暗記している人は居ないでしょうから、このままでは使い物になりません。
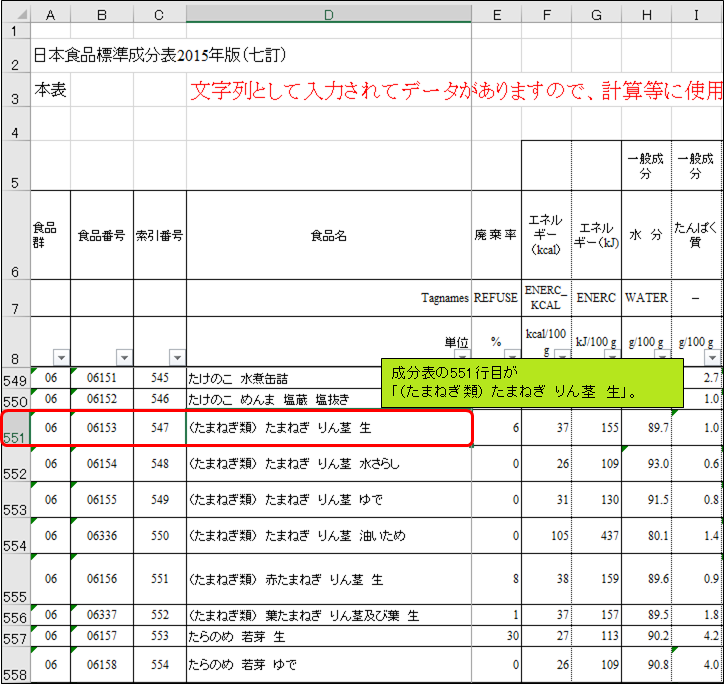
この問題を解決する魔法の記号があります。それは「*」(アスタリスク)です。試しに、G11セルに「*たまねぎ*」と入力して下さい。S11セルが「551」となりました。551は、先程手動で探した「(たまねぎ類) たまねぎ りん茎 生 」の行番号と同じですね。
「*」はワイルドカードと呼ばれており、MATCH関数においては、0文字以上の任意の文字と一致する性質があります。今回のケースでは、MATCH関数の第1引数「*たまねぎ*」の1個目のアスタリスクが、「成分表」551行目の「(たまねぎ類) たまねぎ りん茎 生 」の「(」と一致し、2個目のアスタリスクが「類) たまねぎ りん茎 生 」と一致しました。表にすると下記の通りです。
|
*たまねぎ* (MATCH関数の第1引数:レシピ作成シート!G11セル) |
(たまねぎ類) たまねぎ りん茎 生 (成分表!D551) |
| *(1個目) | ( |
| たまねぎ | たまねぎ |
| *(2個目) |
類) たまねぎ りん茎 生 |
無事「たまねぎ」だけで食品名を取得できましたが、このままではユーザーが毎回キーワードの前後にアスタリスクを付けなければなりません。キーワードに必ずアスタリスクを付けるのであれば、それはExcelにやらせましょう。G11セルから「*」を削除し、S10セルを下記のように書き換え、S29セルまで書式なしコピーしてください。
「=MATCH( $G10 , 成分表!D:D, 0 )」→「=MATCH( “*" & $G10 & “*", 成分表!D:D, 0 )」
なお、「&」は文字列を結合する演算子です。
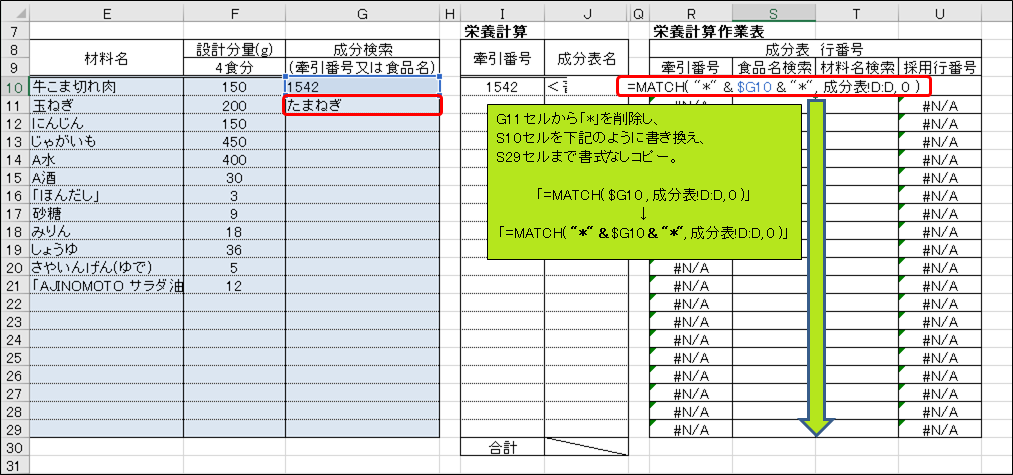
G11セル(たまねぎ)に「*」を入力しなくともS11セルが「551」となりましたが、今度はS12:S29セルの値が「3」となってしまいました。これは、「=MATCH( “**", 成分表!D:D, 0 )」の戻り値で、アスタリスクが0文字以上の任意の文字列と一致するため、「成分表」D列の3行目と一致してしまった結果です(何が入力されているかは自分の目で見てみましょう)。
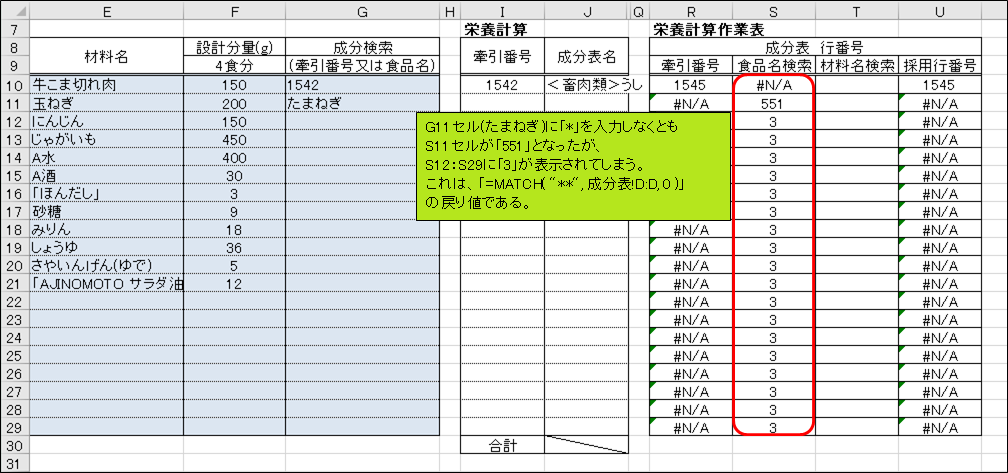
意図しない行番号を抑制するため、S10セルを下記のように書き換え、再度S29セルまで書式なしコピーして下さい。
「=MATCH( “*" & $G10 & “*", 成分表!D:D, 0 )」→=IF( G10 = “", NA() , MATCH( “*" & $G10 & “*", 成分表!D:D, 0 ) )

食品名で検索した行番号を採用行番号セルに反映させます。U10セルを下記のように書き換え、U29セルまで書式なしコピーして下さい。
「=R10」→「=IFERROR(R10, S10 )」
この数式の意味は、最初に牽引番号の検索結果(行番号か#N/Aのどちらか)を確認し、これが行番号ならそのまま行番号を返し、#N/Aなら食品名の検索結果(行番号か#N/Aのどちらか)を返します。

無事、U11セルが玉ねぎの行番号「551」となり、I11セルとJ11セルに玉ねぎの食品情報が表示されました。
続けて、材料名G12セルの入力値「にんじん」の食品情報も取得しましょう。E12に「にんじん」と入力すると、J12セルは「(にんじん類) 葉にんじん 葉 生」となりました。これはにんじんの葉です。肉じゃがに人参の葉を入れる人は少数派であると私は思っておりますので、ここは人参の根の食品情報を取得したい所です。

ここで、GoogleやYahoo!のホームページ検索を思い出して下さい。絞り込み検索をする際は、キーワードをスペースで区切っていましたね。本シートでも同じような絞り込み検索ができれば、人参の根の食品情報を取得できそうです。これには、SUBSTITUTE関数を使用します。
構文
SUBSTITUTE(文字列, 検索文字列, 置換文字列, [置換対象]
|
引数名 |
説明 |
| 文字列 | 必ず指定します。 置き換える文字を含む文字列を指定します。目的の文字列が入力されたセル参照を指定することもできます。 |
| 検索文字列 | 必ず指定します。 置換する文字列を指定します。 |
| 置換文字列 | 必ず指定します。 検索文字列を検索して置き換える文字列を指定します。 |
| 置換対象 |
省略可能です。 検索文字列に含まれるどの文字列を置換文字列と置き換えるかを指定します。 置換対象を指定した場合、検索文字列中の置換対象文字列だけが置き換えられます。 指定しない場合、検索文字列中のすべての文字列が置換文字列に置き換えられます。 |
SUBSTITUTE関数は、文字列中の指定した文字列を、別の文字列に置換する関数です。これを使って、MATCH関数に指定するキーワードのスペースを「*」に変換します。例えば、キーワード(G12セル)に「にんじん 根」を入力した場合、このキーワードがMATCH関数に渡される際、従来は「*にんじん 根*」となっていましたが、SUBSTITUTE関数を使用してスペースを「*」に変換すると、「*にんじん*根*」に変換されます。スペースには全角と半角の2種類がありますが、ユーザーがどちらのスペースを入力するか事前に知ることは出来ませんので、両方とも置換する数式を書きます。
S10セルのMATCH関数の第1引数「$G10」を下記のように書き換え、S29セルまで書式なしコピーします。下記の" “及び" "は半角スペースと全角スペースの文字列定数です。
「$G10」→「 SUBSTITUTE(SUBSTITUTE($G10, “ “, “*"), " “, “*")」
書き換えたS10セルの数式のは下記のようになっています。
「=IF( G10 = “", NA(), MATCH( “*" & SUBSTITUTE(SUBSTITUTE($G10, " “, “*"), “ ", “*") & “*", 成分表!D:D, 0 ) )」

G12セルに「にんじん 根 むき」と入力すると、皮をむいた人参の根の食品情報が取得できます。なお、この数式による絞り込み検索は、キーワードの順序と食品名の単語の並び順が一致している必要があります。例えば、「根 にんじん」というキーワードに一致する食品はありません。ホームページ検索のように、キーワードの順序に影響を受けない絞り込み検索も技術的には可能ですが、実用上それほど支障は無いため、この場では説明しません。

材料名による食品情報の取得
さて、次はE10:E29に入力されている材料名で検索する方法ですが、これは食品名の検索方法とほぼ一緒です。ただ単に、検索キーワードの入力場所が違うだけです。T10セルに「=IF( E10 = “", NA(), MATCH( “*" & SUBSTITUTE(SUBSTITUTE(E10, " “, “*"), “ ", “*") & “*", 成分表!D:D, 0 ) )」と入力し、U10セルの数式「=IFERROR(R10, S10 )」を「=IFERROR(R10, IFERROR(S10, T10) )」に書き換えます。T10:U10セルをT29:U29セルまで書式なしコピーして完成です。13行目のじゃがいもが材料名検索で良い感じの食品情報がヒットしています。
余談ですが、「成分表」の適当な列に、食品の直感的な別名(”牛こま切れ”や”人参”など)」を入力しておき、これをMATCH関数の検索範囲(第2引数)に指定しておくことで、成分検索の手間が大幅に減ります。